New speed record in proving Keccak: Binary GKR
In Ethereum Virtual Machine (EVM), a significant amount of overhead is in proving Keccak, a hash function used in EVM's Merkle Patricia Trees. Proving Keccak efficiently has been an extremely challenging question in the research of zero-knowledge proofs. Polyhedra team has been working on Binary GKR—a proof system that is tailored for Kecaak and other binary operations.
Binary GKR presents a new speed record for proving Keccak—it is about 5.7x faster than FRI-Binius, the state-of-the-art work on binary proof system. We believe that Binary GKR can become a general-purpose "sidecar" for many zkEVM implementations to handle Merkle Patricia Trees for Ethereum state.
Keccak is the Holy Grail
Ethereum is planning to become a ZK layer-1. The Ethproofs initiative, which currently involves 21 teams and 22 ZK(E)VM implementations, has been working on proving all the Ethereum blocks.
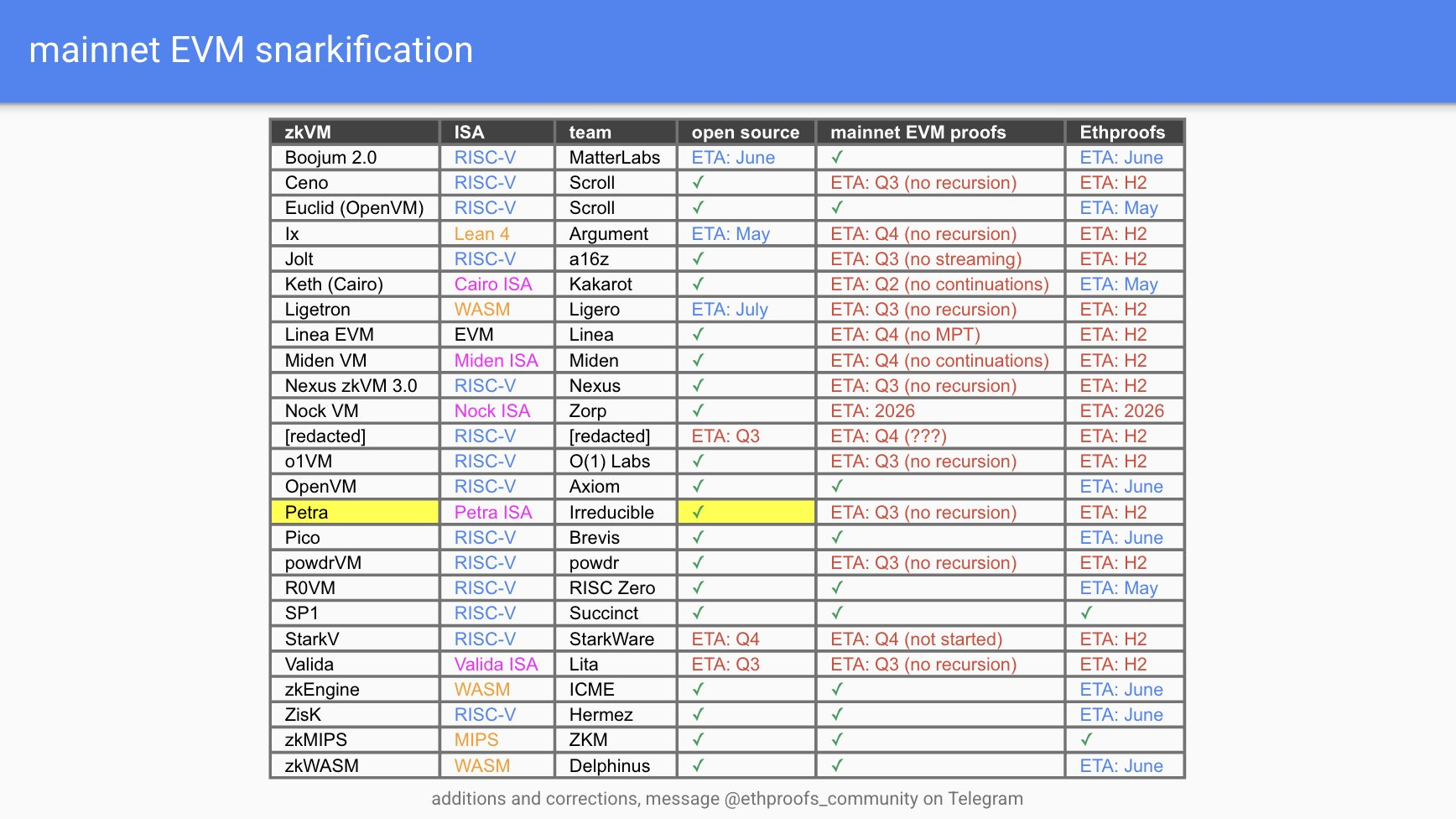
One can already watch the progress in the Ethproofs website, where ZkCloud, Succinct, Snarkify, and ZKM are currently submitting proofs for new blocks produced. The goal is for Ethereum to become a layer-1 where the execution logic gradually moves to the zero-knowledge proofs, and the consensus layer may only need to, for example, propose a list of transactions to be included.
Attempts to build zkEVM have been made in EVM-compatible zkRollups, such as Polygon, Taiko, and Scroll. One problem immediately arising from implementing zkEVM is that some operations that are efficient in regular CPU, thereby becoming the standardized primitives and being adopted in EVM protocols in the very beginning, are not very efficient when being proven in zkEVM. The biggest overhead has been with Keccak, for Merkle Patricia Trees used in Ethereum to compute a hash of the latest state of the entire Ethereum blockchain.
This inefficiency stems from the fact that zero-knowledge proofs generally operate over a prime field, but Keccak is, interestingly, a hash function that operates on the bit level.
To give a high-level idea, we here show the five operations, called theta, rho, pi, chi, and iota, used in the Keccak hash function to see why they are all about "bits". These operations are applied to a 5x5 matrix that consits of 5 rows and 5 columns, with each cell a 64-bit integer, which we call "word".
- \(\boldsymbol{\theta}\) (theta). Compute the parity of each column and apply the exclusive-or operation of the parity of a column to the column on its left, and a similar exclusive-or operation, with a left rotation, to the column on its right. This consists of binary operations like "exclusive-or" and "rotate-left".
- \(\boldsymbol{\rho}\) (rho). Perform a bitwise left rotation to each of the 25 words, while each word is rotated with a different, fixed distance. This consists of "rotate-left".
- \(\boldsymbol{\pi}\) (pi). Relocate the words in a fixed pattern. This is usually a "dummy" operation for ZK, as it is just permuting the words in the matrix.
- \(\boldsymbol{\chi}\) (chi). Perform a bitwise combination operation along the rows, where each word in the same row is being mixed with the word on its left and the word on its right. This consists of "exclusive or", "negation", and "and".
- \(\boldsymbol{\iota}\) (iota). The first word of the matrix is exclusive-or with a constant. This consists of "exclusive or".
The challenge to implement Keccak in zero knowledge proofs is directly about how to represent these binary operations, especially when each operation in Keccak is operated on a 64-bit number. This is also why we refer to the 64-bit version of Keccak as Keccak-1600 because the state has 5 x 5 x 64 = 1600 bits being operated in one round, and there are 24 such rounds. Let me now summarize some previous attempts.
Attempt 1: Groth16 or other R1CS proof systems. The most popular and straightforward way is to implement it using Groth16 or other R1CS proof systems. To represent the binary operations in Groth16, we represent bits as 0 or 1, and we express "exclusive or", "negation", and "and" in arithemtic relations. We do not need to worry about "rotate-left" and other permutations, as they can be handled without any overhead in ZK.
- Exclusive or: \(a+b−2 \times a \times b\)
- Negation: \(1−a\) (can usually be merged into other constraints for free)
- And: \(a \times b\)
We can calculate how many constraints are needed for a full Keccak hash function evaluation. In a single round, \(\theta\) gives 4480 constraints, \(\rho\) and \(\pi\) are free, \(\chi\) gives 3200 constraints, and \(\iota\) gives 64 constraints. Since there are 24 rounds, this adds up to 185856 constraints for a full Keccak evaluation in Groth16.
Using the number from Ingonyama's ICICLE library, we can see that it takes about 30-40ms to generate the proof for a single Keccak over Nvidia 4090 GPU (and about 450ms for ICICLE on CPU). If we want to prove 8192 Keccak evaluations, it would take at least 250-300 seconds for GPU, and about one hour for CPU.
Attempt 2: Lookup-based proof systems. A more modern approach is to operate data in a batch, such as every 4 bits, and use lookup to implement all the binary operation over a chunk of bits. In other words, each 64-bit integer is sliced into, for example, eight 8-bit chunks, and we employ a list of lookup tables.
- a lookup table of size \(2^8 \times 2^8 \) for "exclusive or" between two 8-bit chunks. This allows one to effectively do an 8-bit XOR using one constraint instead of eight.
- a lookup table of size \(2^8 \times 2^8 \) for "and" between two 8-bit chunks, with the same benefit as above.
- several lookup tables to take care of "rotate-left", which are usually implemented as follows: seven tables each of size \(2^8\), each dealing with "rotate-left" for a distance of \(8k+1\), \(8k+2\), ... with \(k\) an non-negative integer. Note that this introduces an additional overhead compared with Attempt 1, as Attempt 1 does not need to handle "rotate-left". This roughly adds 192 constraints to each round, which is a relatively small overhead compared with others.
To implement this kind of system, we would not be using Groth16. In fact, it is better done using a small-field proof system like Stwo or Plonky3, which also has extensive support for lookup tables. This would improve over the Groth16 approach significantly, with about 27264 constraints to be evaluated as well as the lookup tables for each full Keccak evaluation. This, however, may end up slower, since the cost of the lookup table may outweigh the benefit. Its performance might not be better than Attempt 1.
Attempt 3: Binius. Since the improvement from using lookup (or equivalently, customized gates) might not be better due to the inherent cost of lookup in comparison of the level of improvement it can bring, one will need to explore other ways to prove Keccak faster.
This comes back to why Keccak is the holy grail. Previously, we have other hash functions like SHA-256 and Blake2/3, these hash functions also have binary opeartions like "exclusive or" and "and", but a lot of overhead comes from "integer addition", which we can obtain a big speedup by operating on 4-bit chunks. This is not the case for Keccak. Keccak simply has none of such integer additions. As a result, prior techniques for optimizing these classic hash functions do not work for Keccak.
The state-of-the-art solution to address this is Binius, which explores the fact that, since Keccak only involves bit operations, we can implement it in a proof system that uses bits as the native unit. This comes to Binius. In Binius, Keccak is expressed as computation over a finite field \(\mathcal{F}_2\). All the overheads related to "exclusive or" are basically eliminated, as they are simply additions in \(\mathcal{F}_2\). Keccak will be represented as a sequence of polynomial operations. Rotations can be handled easily as long as we treat bits as individual bits. The overhead would be dominated by the "and" gates in \(\chi\).
A benchmark for Binius in proving 8192 Keccak evaluations shows that it can generate the proof in 12.35 seconds. This is significantly better than Groth16 (Attempt 1) and lookup-based approach (Attempt 2).
Is Binius the end? We show that one can indeed do better than Binius, and in particular, achieve a five times speedup by eliminating some redundancy in proving Keccak.
Binary GKR
Polyhedra team is building the Binary GKR (https://eprint.iacr.org/2025/717.pdf), which is a new solution that incorporates several techniques to improve proving binary operations, with Keccak as a special case. There are three key techniques.
GKR. We base our design on the GKR protocol because it can reduce the redundancy in handling repeated computation. We can expect that the Keccak prover will serve as a "sidecar" for zkEVM and processes a number of Keccak evaluations delegated by the zkEVM. Therefore, the circuit that our protocol is handling is going to have a lot of repetitions (e.g., 8192 Keccak). In addition, Keccak itself has a lot of repetitions: it performs similar operations over the 5x5 matrix, it performs the same steps in 24 rounds. This makes it a natural candidate for the GKR protocol, where the verifier efficiency is low, and the prover can leverage such pattern to simplify computation.
Binary-field polynomial commitment. We use a polynomial commitment scheme based on linear codes that operate directly on the binary field. As we mentioned before, using a binary native representation allows us to, for example, get "exclusive or" for free. In addition, same as in Binius, a binary-field polynomial commitment scheme removes the redundancy in comparison to using a much larger field that we do not need.
Precomputed tables for binary operations. The key novelty in the Binary GKR paper is that the GKR protocol can also be made much more efficient due to high sparsity. This sparsity remains even if we want to process several bits together. What we do is to "pack" several bits into the polynomials in the GKR protocol (note that we do not need to commit these polynomials, as they are intermediate polynomials in GKR), and the GKR protocol performs operations directly on the packed data. The sparsity is still high, so we are able to employ precomputed tables that allow the prover to compute the proof using much less computation overhead than regular GKR protocols.
We will focus on the third technique in this article.
Pack bits in polynomials
At the core of our scheme is a novel approach for performing sumchecks in GKR protocol tailored to data-parallel boolean circuits, significantly reducing the prover's workload.
Specifically, to prove \(N\) binary operations, our prover does only \(O(N/\log N)\) field operations, by representing the computation in \(B=(\logN)/3\) parallel sub-circuits.
Let \(V_i: \{0,1\}^{s_i}\rightarrow \mathbb{F}\) denote the gate outputs in layer \(i\). For data-parallel circuits, the index \(g\in\{0,1\}^{s_i}\) can be broken down into two pieces \((p,b)\), where \(p\in\{0,1\}^{\ell_i}\) is the index of gates in each sub-circuits and \(b\in\{0,1\}^{\log B}\) is the index of the sub-circuits.
$$V_{𝑖-1}(𝑔) = 𝑉_{i-1}(𝑝, 𝑏 )$$
GKR proves the relationship between two adjacent layers, for example, \(V_{i−1}\) and \(V_i\). GKR is to show that the two layers satisfy the following relationship, for any \(b\in\{0,1\}^{\log B}\) and any \(x,y\in\{0,1\}^{\ell_i}\) where \(\ell_0+\ell_1=\ell\). For simplicity, in this article, we focus on multiplication, or, the "and" gate:
$$V_{i-1}(\tilde{𝑝}, \tilde{b})=\sum_{x, y,b} {𝑒𝑞}_𝑝(𝑏, \tilde{𝑏}) \cdot {𝑚𝑢𝑙}_{𝑖−1}(\tilde{𝑝}, 𝑥 , 𝑦 ) \cdot 𝑉_𝑖 ( 𝑥 , 𝑏 ) \cdot 𝑉_𝑖 ( 𝑦 , 𝑏 )$$
The traditional representation with multilinear extension above would require \(\ell+\log B\) variables to represent all outputs. We can indeed create a virtual value, \(b\), that represents a polynomial of degree \(B−1\), and rewrite the relationship as follows. This effectively lets us process \(B\) bits in one shot, which we will leverage soon.
$$V_{i−1}(\tilde{p},\tilde{b})=\sum_{x,y,b}L_b(\tilde{b})\cdot {mul}_{i−1}(\tilde{p},x,y)\cdot V_i(x,b)\cdot V_i(y,b)$$
where $L_b$ is a lagrange polynomial that we will evaluate in a special way.
Evaluate binary relations faster
Binary GKR, unlike GKR, presents new optimization opportunities. Previously, in GKR, when we reason about the relationship between two layers, we perform a sumcheck. This sumcheck has the prover evaluate the \(V_{𝑖 − 1}\) polynomial from above over \(𝑥\) and \(𝑦\), in total \(2^\ell\) locations.
$$V_{i−1}(\tilde{p},\tilde{b})=\sum_{x,y,b} L_b(\tilde{b})\cdot {mul}_{i−1}(\tilde{p},x,y) \cdot V_i(x,b)\cdot V_i(y,b)$$
Our observation is that \(V_i(x,b)\) and \(V_i(y,b)\) are indeed very sparse. Take \(V_i(x,b)\) for example. There are only \(2^B\) possible unique combinations, and same for \(V_i(y,b)\). So, instead of having the prover compute all outcomes, which is a grand summation of size \(2^{2\ell}\), it indeed only requires \(2^{2B}\), which is smaller.
Let \(g(b)=\sum_{t\in[B]}L_t(\tilde{b})\cdot L_t(b)\), and \(g_{x,y}(b) = g(b)\cdot \tilde{v}_i(x,b) \cdot \tilde{v}_i(y,b)\).
We can rewrite all the terms as \({mul}_{i−1}(\tilde{p},x,y)\cdot g_{x,y}(b)\). We only need to compute all possible combinations of \(g_{x,y}(b)\), store them in a bookkeeping table, and we can compute the sum by looking up the table. Algorithm 1 shows how to precompute this table.

If \(B=8\) and the underlying field has size \(\log|\mathbb{F}|=128\), the preprocessed table contains \(2^{2B}=2^{16}\) elements, each requiring a single polynomial multiplication. Consequently, a total of \(2^{16}\) polynomial multiplications is performed.
The bookkeeping table is small. With proper parameters, we can control the size of the table to be about 15MB. This fits comfortably within the CPU's L3 cache, making table lookup very efficient.
This technique is general to almost all binary operations, and is the key of the performance improvement in the Binary GKR construction.
Implementation and Evaluations
We have implemented our SNARKs based on the Rust arkworks ecosystem and conducted comprehensive benchmarks on randomly generated Boolean circuits of varying sizes.
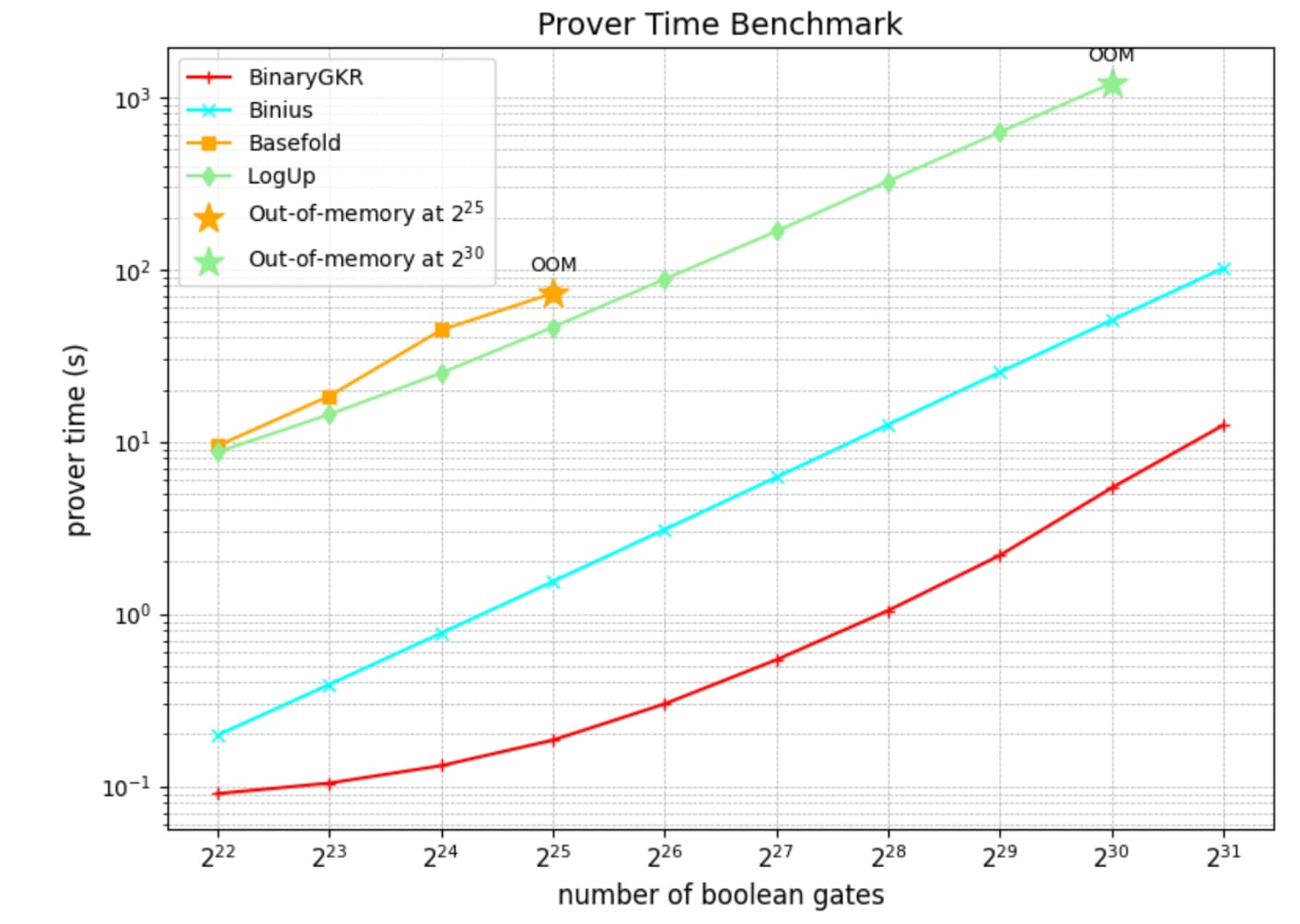
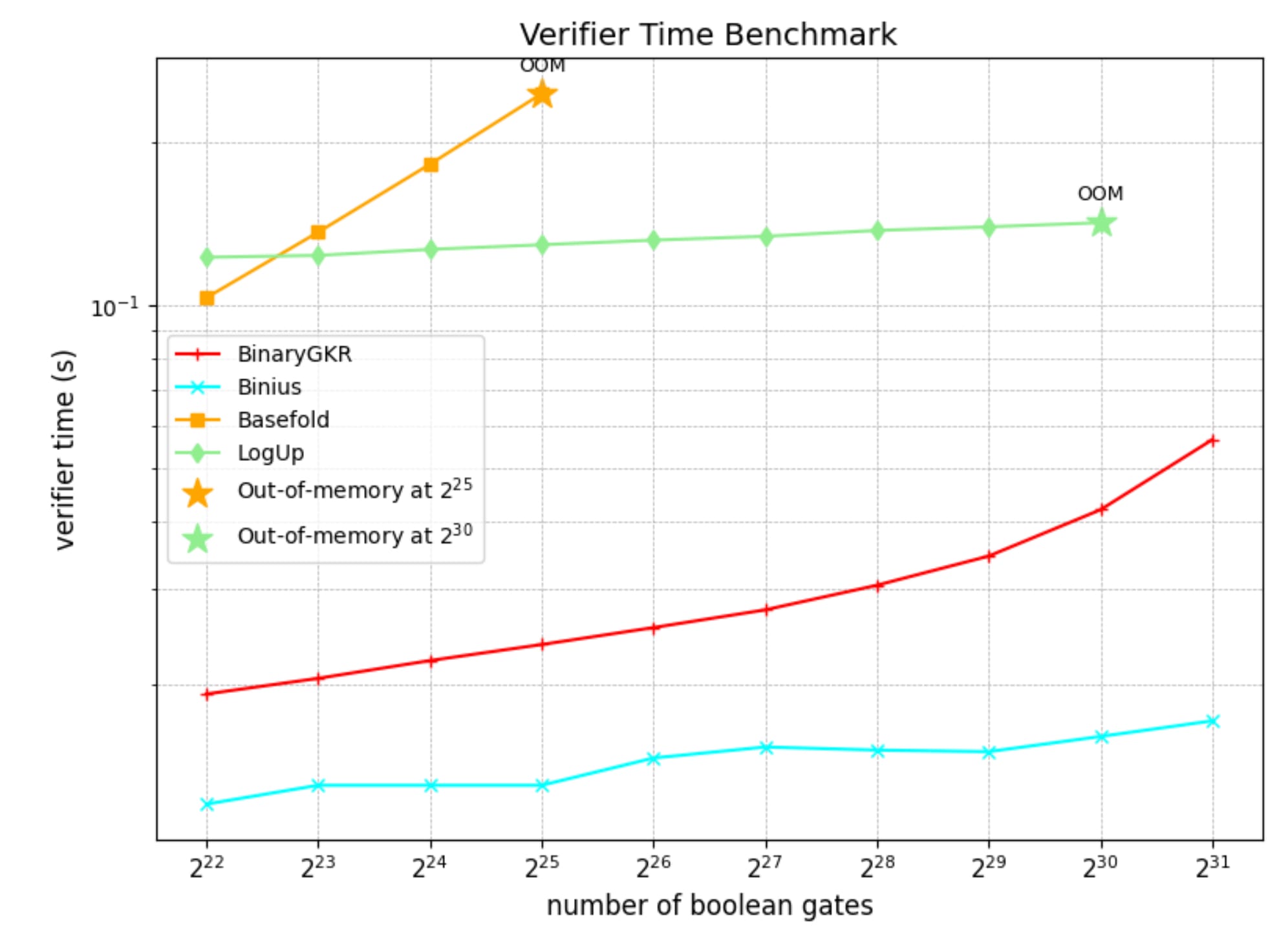
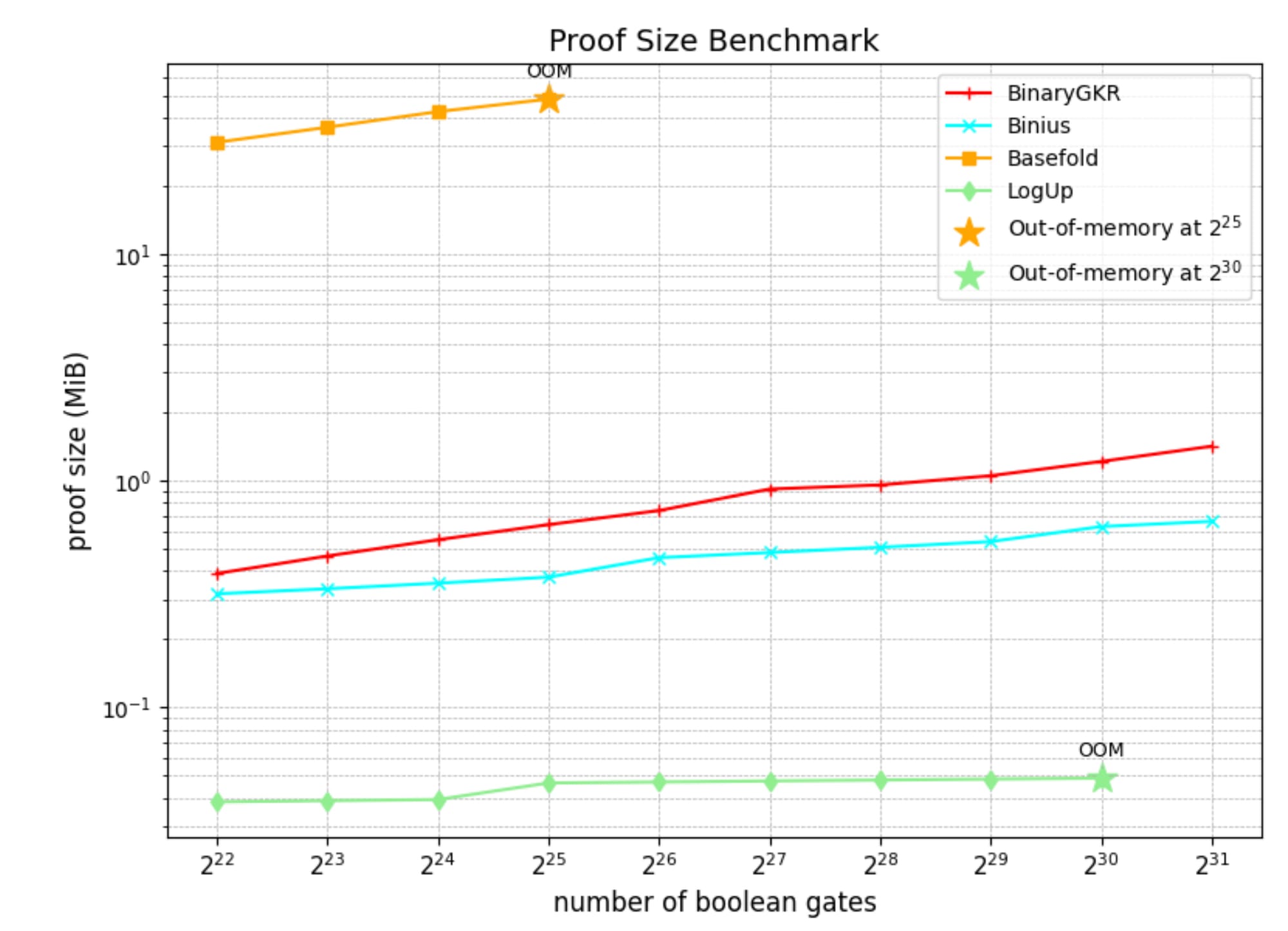
Other than random Boolean circuits, we also focus on that holy grail–-Keccak. We compare our approach with Binius on Keccak proofs. Both systems operate over binary fields. For 8192 Keccak invocations, Binius takes 12.35 seconds to generate a proof, while our system takes just 2.18 seconds. Our approach also has a better verifier time: 0.035 seconds, due to the simple structure of Keccak. In terms of communication cost, our proof size is 1.052 MB.
| Protocol | Prover Time (s) | Verifier Time (s) | Proof Size (MB) |
|---|---|---|---|
| Binius | 12.35 | 0.213 | 0.548 |
| BinaryGKR | 2.183 | 0.035 | 1.052 |
Conclusion
In this article we talk about Polyhedra team's latest work in zero-knowledge proofs, specifically on optimizing binary functions like Keccak, which can be a useful "sidecar" to all the zkEVM constructions.
We expect to integrate Binary GKR to other zkEVM systems, such as RISC Zero and SP1, and see how Binary GKR can help address the Keccak bottleneck and enable the Ethereum's long-term goal of moving to full snarkification of the layer-1, without breaking changes to the existing EVM systems.