Kernel-Wise Proving for Machine Learning Models
"How do you eat an elephant? One bite at a time."
Machine learning models have advanced at an incredible pace in recent years. As their capabilities grow, so does their complexity—today’s models often contain millions or even billions of parameters. To cope with this scale, a variety of zero-knowledge proof systems have been developed, each striving to balance proving time, verification time, and proof size.
Table 1: The Increasing Number of Model Parameters
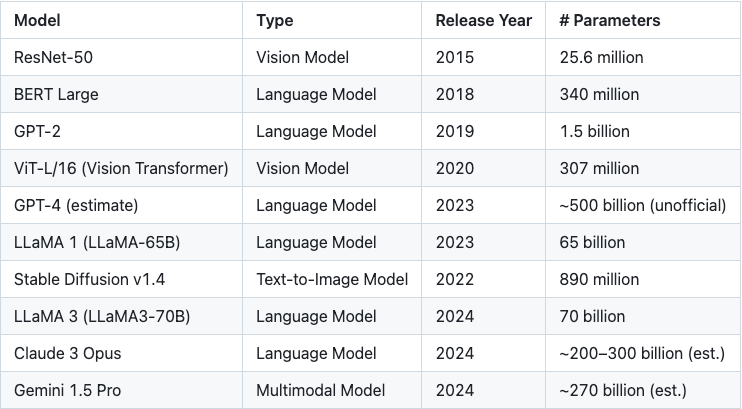
While much of the focus has been on optimizing the proof systems themselves, one crucial angle has received less attention: partitioning large models into smaller, more manageable components for proving. You might be wondering—why does this matter?
Let me explain.
Why Partition Large Machine Learning Models?
Modern machine learning models can contain billions of parameters, consuming significant memory even before any cryptographic processing. The challenge becomes far more daunting in the context of zero-knowledge proofs (ZKPs). Each floating-point parameter must be converted into an arithmetic field element, often increasing memory usage by 5–10×. On top of that, accurately simulating floating-point operations in a field requires additional overhead—let's say another 5×.
Combined, these transformations can lead to a 25–50× increase in memory requirements. For example, a model with 1 billion 32-bit parameters could demand 100–200 GB just to store the converted parameters. Once you factor in intermediate values and the overhead from the proof system itself, total memory usage can easily reach the terabyte scale.
Popular proving systems like Groth16 and Plonk, when implemented naively, assume all relevant data fits in memory. While not impossible, these demands impose serious constraints on the hardware available for proving.
PolyHedra's Solution: zkCuda
What is zkCuda
As mentioned in our zkCuda Tech Doc:
Polyhedra's zkCUDA provides a robust development environment for creating high-performance circuits. With zkCUDA, you can harness the power of the backend prover and hardware parallelism to accelerate proof generation without sacrificing the expressiveness of circuits. The language will be familiar to CUDA users, featuring similar syntax and semantics, and is implemented in Rust.
zkCUDA enables you to:
- Easily develop high-performance circuits.
- Efficiently leverage the power of distributed hardware and highly parallel systems like GPUs or MPI-enabled clusters.
Why zkCuda?
zkCuda is a GPU-inspired computing framework that partitions large machine learning models into smaller, manageable kernels using a CUDA-like frontend language. This design brings several key advantages:
Tailored Backend Selection: zkCuda enables fine-grained analysis of individual computation kernels and allows each to be paired with the most suitable zero-knowledge proving system. For instance, highly parallel kernels may benefit from protocols like GKR, which excel at handling structured parallelism. In contrast, smaller or irregular kernels might be better served by systems like Groth16, which offer low overhead for compact computations.
Smarter Resource Allocation: Different proving kernels can have vastly different demands on CPU, memory, and I/O. zkCuda helps estimate these resource requirements and enables efficient scheduling to maximize throughput. Even better, it supports distributing proof tasks across heterogeneous computing platforms—including CPUs, GPUs, and FPGAs—making full use of available hardware for optimal performance.
The Resonance between ZKCuda and GKR
While zkCuda is designed to be a flexible framework compatible with various proving systems, it naturally aligns especially well with the GKR (Goldwasser-Kalai-Rothblum) protocol.
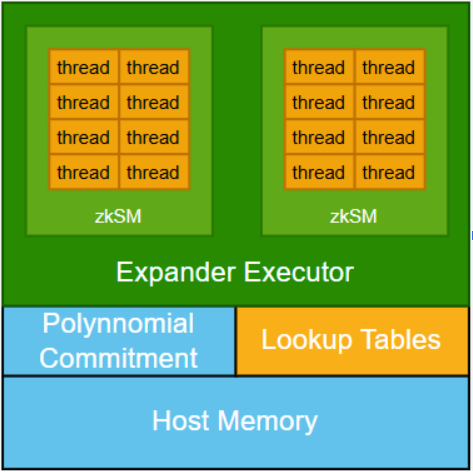
At the architectural level, zkCuda introduces polynomial commitments to connect separate kernels, ensuring that all sub-computations operate on consistent shared data. These commitments are essential for maintaining soundness, but they also come with high computational costs.
However, GKR offers a more efficient alternative. Unlike other systems that require each kernel to fully prove its internal satisfiability, GKR allows us to recursively reduce correctness from a kernel’s outputs back to its inputs. This means we can propagate correctness claims across kernels, rather than fully resolving them within each one. Conceptually, this is reminiscent of gradient backpropagation in machine learning, where correctness is traced backward through the computation graph.
Merging these "proof gradients" from multiple paths can be slightly more complex, but it’s this very paradigm that creates a deep synergy between zkCuda and GKR. By aligning with the structure of ML training workflows, we believe zkCuda can achieve tighter integration and improved performance in zero-knowledge proof generation for large models.
Preliminary Result and Future Direction
We have completed the initial development of the zkCuda framework and successfully tested it on cryptographic hash functions like Keccak and SHA-256, as well as on small-scale machine learning models.
Looking ahead, we are excited to explore the rich set of engineering techniques used in modern machine learning training, such as memory-efficient scheduling and graph-level optimization. We believe integrating these ideas into our proving framework will unlock even greater performance and flexibility—and we’re eager to take that next step.