Scaling Trust in the Age of Artificial Intelligence
First Practical Zero-Knowledge Proof System to Verify Transformer and Large Language Models
Introduction
Trust plays a crucial role in our everyday lives, shaping our interactions in ways we often take for granted. Imagine unlocking your phone with facial recognition, applying for a loan through an AI system, or receiving an AI-powered medical diagnosis. How can you be sure these AI systems are treating you fairly and protecting your privacy? As artificial intelligence increasingly shapes our daily lives, we face a critical challenge: building trust in AI systems while protecting sensitive information on all sides.
Consider a hospital using an AI system for cancer diagnosis. The hospital needs proof the AI performs consistently and accurately, but the AI provider can’t share proprietary model details. Meanwhile, patient privacy must be protected. Or picture an autonomous vehicle accident — how do we definitively determine whether the AI or human driver was at fault? Traditional approaches to AI transparency fall short in these scenarios, as they typically require exposing sensitive details that could compromise security, privacy, or intellectual property.
Zero-knowledge machine learning (zkML) offers a breakthrough solution to these real-world challenges. Several years ago, we first introduced the notion of zero-knowledge machine learning (zkML) in our seminal work “Zero Knowledge Proofs for Decision Tree Predictions and Accuracy” [1], which demonstrated how to construct zero-knowledge proofs for both predictions and accuracy of decision tree models. This innovative technology enables mathematical verification of AI systems while keeping sensitive information private. For example, a bank can prove its loan approval AI treats all applicants fairly without revealing its proprietary algorithms. Healthcare providers can verify AI diagnostic results while protecting both patient data and model details. And in the future, zkML could provide definitive proof of decision-making processes in accidents involving AI systems, clearly establishing responsibility between human and AI agents.
The applications of zkML extend across industries. Financial institutions can demonstrate regulatory compliance of AI trading systems without exposing strategic advantages. Employers can prove their AI recruitment tools are unbiased while protecting candidate data. Smart home devices can verify they protect user privacy while delivering personalized services. Government agencies can audit AI systems for fairness and safety without compromising security.
However, implementing zkML in practice faces significant challenges. Current systems require substantial computational resources, making real-time verification difficult for complex AI models. Integration with existing AI development workflows remains cumbersome, requiring specialized expertise. While research has shown zkML’s potential with various AI architectures — from decision trees to large language models — creating practical, user-friendly tools for widespread adoption remains a work in progress.
Summary of Innovation
The performance of our zkML technology represents a significant leap forward in the field of secure machine learning. By achieving a performance improvement of four orders of magnitude over previous approaches, we have drastically reduced the time and computational resources required for proof generation. This enhancement is exemplified by Expander’s ability to generate proofs for the Llama-3 model with 8 billion parameters in just minutes using a high-performance CPU. Such efficiency was previously unattainable and sets a new benchmark for what’s possible in zkML applications.
Moreover, this advancement marks the first time zkML has been successfully scaled to accommodate modern transformers of this size. Scaling zkML to work with large-scale, state-of-the-art models like Llama-3 not only demonstrates the robustness of our technology but also its applicability to real-world, high-performance machine learning tasks. This breakthrough enables secure and efficient deployment of complex models, ensuring that robust fraud prevention mechanisms can be implemented without sacrificing system performance or scalability.
Besides groundbreaking performance, Polyhedra has also developed zkPyTorch, a revolutionary compiler framework for zero-knowledge machine learning that seamlessly integrates with PyTorch. This groundbreaking system represents more than just a toolchain — it’s the first comprehensive compiler framework that enables direct translation of standard PyTorch models into zero-knowledge circuits. zkPyTorch dramatically simplifies zkML implementation through automated optimization and compilation, enhancing AI model security and privacy while ensuring compliance with standards. It sets a new benchmark for secure AI deployment in real-world applications and fundamentally transforms how developers can build verifiable AI systems.

As AI systems become more prevalent and sophisticated, the ability to verify their behavior while protecting sensitive information becomes increasingly crucial. zkML provides a mathematical foundation for building trustworthy AI systems that respect privacy, ensure consistency, and enable clear accountability.
Addressing these challenges requires more than just research — it demands a team capable of turning theory into practical solutions. At Polyhedra Network, we combine expertise in zero-knowledge proofs and AI with hands-on engineering experience to bridge this gap. Our work is carried out in close collaboration with researchers from the Berkeley Center for Responsible, Decentralized Intelligence (RDI), building on a shared legacy of innovation in ZK technology and decentralized systems.
Our work, such as verifying large language models like Llama-3 8B, showcases our ability to handle complex AI architectures and advance zkML technology. With a focus on usability and scalability, we develop solutions that bridge the gap between research and real-world applications. By integrating zkML into frameworks like PyTorch, we aim to make this technology accessible and practical for a wide range of industries.
Zero-knowledge Machine Learning in a nutshell
zkML leverages zero-knowledge proofs to enable verification of ML computations while preserving the privacy of models, input data, or both. Through this technique, one party can prove to another that they correctly conduct inference on a given model and a given input without revealing any sensitive information — whether that’s model parameters, input data, or intermediate computations.
Since our pioneering work [1], zkML has emerged as a fundamental approach for privacy-preserving machine learning applications, particularly in scenarios where both privacy and verifiability are essential requirements. A key functionality that zkML enables is non-interactive verification of inference — a service provider can generate a zero-knowledge proof demonstrating that a given output was legitimately produced by running the specified model on the input, whether it’s a decision tree, neural network, or other ML architecture.
Beyond verifiable inference, zkML’s capabilities extend to:
- AI Model Audit: Verifying a model’s performance on a specified test set through zkML, ensuring accuracy and compliance without revealing sensitive model or data details. This can be particularly useful for AI safety.
- Training Data Origin Verification: Tracing and proving the lineage and authenticity of training data
- Authenticated Data Labeling: Verifying the integrity of data labeling processes
- Training Process Verification: Ensuring model training adheres to specified protocols and requirements.
This comprehensive approach to verification addresses the full lifecycle of machine learning systems, from data preparation through model deployment and inference, establishing zkML as a cornerstone technology for trustworthy AI systems.
Challenges and solutions
The past four years have witnessed remarkable advancements in zkML technologies since our groundbreaking work in zkDT [1]. The field has expanded significantly, with subsequent innovations including zkCNN [2, 3, 12] and zkLLM [11], which extended zero-knowledge proof systems to neural networks and large language models respectively. Our pioneering contributions didn’t stop at theoretical foundations — we developed new, advanced distributed proving systems in [4,5,6,7] that have pushed the boundaries of what’s possible in zkML.
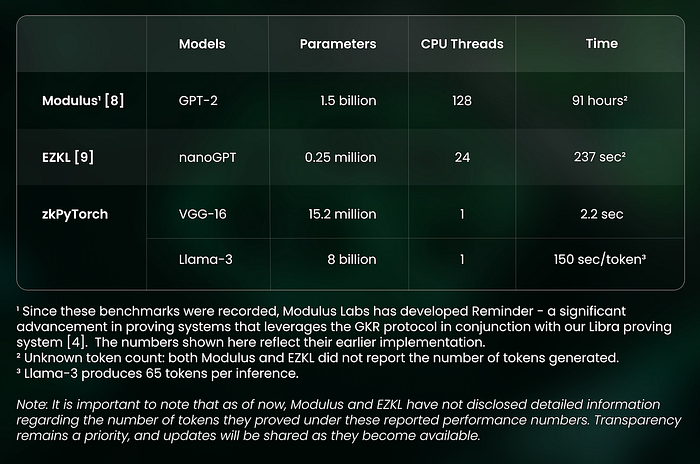
On the practical front, we’ve seen encouraging adoption of these ideas in real-world applications. Notable implementations include zero-knowledge proofs for nanoGPT (developed by the EZKL team [8]) and GPT-2 (developed by Modulus Labs [9]). These projects demonstrate the practical viability of zkML concepts, while also highlighting key challenges in the field.
However, significant challenges remain that our ongoing work aims to address:
- Performance Limitations: Current proving systems like Halo2, when applied to models such as nanoGPT and GPT-2, achieve only sub-hundred parameters per second even on high-performance servers. This falls significantly short of practical requirements for real-world applications, where modern ML models contain billions of parameters. This performance gap represents a critical barrier to deploying zkML solutions at scale.
- Developer Accessibility: The current ecosystem requires developers to write customized circuits for ML models, demanding expertise in both cryptography and specialized programming languages. This steep learning curve presents a significant barrier to widespread adoption.
These challenges underscore the importance of our continued work in advancing zkML technologies, particularly in developing more efficient proving systems and creating more developer-friendly tools and frameworks.
Our Solutions
Expander
We developed Expander, the world’s fastest ZK prover, implementing the next generation GKR protocol. With Expander we achieved an unprecedented 2.16 million Poseidon hashes per second on an AMD Ryzen 7950X3D and scales up to 16M hashes per second on 256-core server hardware [13]. This represents a transformative advancement for zkML implementations.
The performance breakthroughs are remarkable: we can prove VGG-16 with 15.2 million parameters in around 2 seconds on a single core CPU. We can also prove Llama-3 with 8 Billion parameters in around 2.7 hours on a single core CPU. Amortized, we can prove 0.8 million parameters per second, that is 4 orders of magnitude faster than any number previously reported as shown in the table below.
And we didn’t stop here. We recognize that 166 minutes per 65 token inference is still far from ideal for practical applications. We are actively building hardware accelerations for our scheme [10] and developing a distributed prover infrastructure where multiple nodes can collaboratively work on the same proofs [6, 7]. Through these innovations, we are moving steadily toward our goal of real-time proving — where proof generation matches inference speed, effectively eliminating latency in the user experience.
zkPyTorch
In the ZK community, we have observed that developer accessibility remains a major obstacle to widespread adoption. Developers consistently express frustration about the need to learn new languages and understand sophisticated mathematics for zkML development. To address this challenge, we’ve developed a groundbreaking solution: a specialized compiler that works directly with PyTorch, eliminating the traditional barriers to zkML development.
Our compiler bridges the gap between AI and ZK by offering native PyTorch support, allowing developers to continue writing standard PyTorch code without learning new ZK-specific programming patterns. This seamlessly integrates with existing ML workflows while providing automated circuit optimization under the hood. The compiler intelligently translates PyTorch operations to ZK circuits and implements built-in optimizations for common ML patterns, ensuring efficient memory and computation layouts.
We implemented several proof system optimizations in our compiler. These focused primarily on faster computation verification for common mathematical operations. For example, we improved the speed of verifying Fast Fourier Transform calculations by reducing the number of required steps. We also made matrix multiplication checks more efficient through improved circuit design. These changes helped make our compiler’s verification process faster while maintaining correctness.
On the AI side, we utilize PyTorch alongside the XLA compiler to perform efficient and commonly used optimizations. Additionally, by leveraging the precomputed inference results, we significantly accelerate the verification process by treating the inference result as a prefill to the model. We also rely on the latest quantization result, which can significantly reduce the number of FP32 multiplication operations.
The end-to-end pipeline handles everything from automatic circuit generation to integration with our Expander proving system, culminating in a streamlined deployment process. This comprehensive approach dramatically reduces development time from months to days for complex models, eliminates the need for ZK expertise, and ensures code maintainability through standard PyTorch practices. Perhaps most importantly, our solution is future-proof — as ML models evolve, developers can easily update their implementations without learning new ZK-specific techniques.
Future directions
While our current achievements with Expander and zkPyTorch represent significant breakthroughs in zkML, we see several promising directions for further optimization and enhancement:
- Smaller Finite Field Implementation Our current implementation uses BN254 curve, but migration to Mersenne-31 fields could potentially yield up to a 10x performance boost by reducing computational overhead in finite field operations.
- Multi-Machine Multi-GPU Support We are developing support for distributed computing environments leveraging multiple machines and GPUs, enabling parallel proof generation and efficient workload distribution for large-scale models.
- Extended Output Sequence Length While currently optimized for single-token output verification, we are developing optimizations to support efficient verification of longer output sequences, reducing per-token proving overhead and enabling practical applications requiring extended output generation.
- ZK-Friendly Quantization Techniques We are researching quantization methods specifically optimized for zero-knowledge proofs, focusing on minimizing arithmetic complexity in finite fields while maintaining model accuracy.
- Better compiler optimization Our compiler pipeline can be further optimized, potentially reducing both circuit size and proving time.
These improvements will work synergistically with our existing optimizations to further reduce proving time and increase throughput. Our commitment to advancing zkML technology remains steadfast, and we welcome collaboration from the community as we work towards these
Applications
zkML applications span both Web2 and Web3 environments, each with distinct value propositions. In Web2 settings, zkML serves as a premium verification layer for model providers, enabling two crucial trust guarantees. First, it provides proof to users that the correct model is being applied to the correct data, acting as a safeguard against both malicious service providers and potential model misbehavior. Second, as established in our zkDT paper [1], it offers a rigorous method to verify model accuracy by enabling providers to generate proofs of correct inference across large sets of input data. Together, these capabilities create a compelling value proposition that providers can offer as a premium service.
In Web3 environments, zkML serves a dual purpose of ensuring verifiability and privacy. On the verifiability front, we’ve pioneered the concept of Opportunistic zkML Proofs, implementing a challenge-based verification system where proofs are generated only when service providers are challenged. This approach offers numerous advantages: it reduces computational overhead during normal operation, creates strong fraud deterrence through economic incentives, lowers transaction costs when unchallenged, and enables better throughput for applications where immediate verification isn’t critical. The system provides flexible security, allowing applications to balance performance and security based on their specific needs.
Privacy protection is important in systems that need to handle sensitive information. zkML makes it possible to keep data, models, and computations private while still allowing others to verify results. This ensures that both confidentiality and trust can be maintained across various applications.
In both worlds, our solution is designed with regulatory compliance as a primary consideration, implementing privacy as an opt-in feature. We’ve developed regulatory-first privacy controls that can be enabled based on specific requirements, with configurable settings to meet different regional and national regulations. The platform maintains a transparent mode by default when privacy features aren’t required, while providing clear tracking of privacy settings for regulatory reporting and audits. This flexible approach supports diverse use cases across sectors: from full transparency for public sector applications to HIPAA-compliant controls for healthcare, specialized settings for financial services, and configurable options for cross-border operations requiring compliance with multiple jurisdictional requirements.
Looking Forward
As we continue to develop zkML techniques alongside our Expander system, we’re committed to making AI systems more transparent, verifiable, and trustworthy, while respecting regulatory requirements and privacy needs. The zkML technology opens new possibilities for:
- Secure AI Model Deployment
- Verifiable Training Processes
- Configurable Privacy Controls
- Decentralized AI Ecosystems
- Novel AI Applications and Services
We envision our solution as a foundational platform that will enable the next generation of verifiable AI applications. The examples shared here are just the beginning of what’s possible with this technology.
Stay tuned for more updates as we build the future of verifiable AI systems.
References:
[1] Zhang, J., Fang, Z., Zhang, Y., & Song, D. (2020). Zero Knowledge Proofs for Decision Tree Predictions and Accuracy. In Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security (CCS ‘20).
[2] Feng, B., Qin, L., Zhang, Z., Ding, Y., & Chu, S. (2021). ZEN: An Optimizing Compiler for Verifiable, Zero-Knowledge Neural Network Inferences. Cryptology ePrint Archive, Paper 2021/087. Available at: https://eprint.iacr.org/2021/087
[3] Liu, T., Xie, X., & Zhang, Y. (2021). zkCNN: Zero Knowledge Proofs for Convolutional Neural Network Predictions and Accuracy. Cryptology ePrint Archive, Paper 2021/673. Available at: https://eprint.iacr.org/2021/673
[4] Xie, T., Zhang, J., Zhang, Y., Papamanthou, C., & Song, D. (2019). Libra: Succinct Zero-Knowledge Proofs with Optimal Prover Computation. Cryptology ePrint Archive, Paper 2019/317. Available at: https://eprint.iacr.org/2019/317
[5] Zhang, J., Xie, T., Zhang, Y., & Song, D. (2019). Transparent Polynomial Delegation and Its Applications to Zero Knowledge Proof. Cryptology ePrint Archive, Paper 2019/1482. Available at: https://eprint.iacr.org/2019/1482
[6] Liu, T., Xie, T., Zhang, J., Song, D., & Zhang, Y. (2023). Pianist: Scalable zkRollups via Fully Distributed Zero-Knowledge Proofs. Cryptology ePrint Archive, Paper 2023/1271. Available at: https://eprint.iacr.org/2023/1271
[7] Xie, T., Zhang, J., Cheng, Z., Zhang, F., Zhang, Y., Jia, Y., Boneh, D., & Song, D. (2022). zkBridge: Trustless Cross-chain Bridges Made Practical. In Proceedings of the 2022 ACM Conference on Computer and Communications Security (CCS ‘22).
[8] Modulus Labs. (2024). Chapter 14: The World’s 1st On-Chain LLM. Medium. Available at: https://medium.com/@ModulusLabs/chapter-14-the-worlds-1st-on-chain-llm-7e389189f85e
[9] EZKL. (2023). Honey I SNARKED the GPT. Available at: https://blog.ezkl.xyz/post/nanogpt/
[10] Polyhedra Network. “Accelerating Ethereum’s Verge: Harnessing GPU Power for Zero-Knowledge Proofs.” GitHub Repository, PolyhedraZK/blogs, 2024. https://github.com/PolyhedraZK/blogs/blob/main/blogs/sumcheck_cuda.md.
[11] Sun, H., Li, J., & Zhang, H. (2023). “zkLLM: Zero Knowledge Proofs for Large Language Models.”
[12] D. Kang, T. Hashimoto, I. Stoica, and Y. Sun, “Scaling up Trustless DNN Inference with Zero-Knowledge Proofs,” arXiv preprint, Oct. 2022. [Online]. Available: arXiv:2210.08674
[13] Expander performance. https://medium.com/polyhedra-network/expander-still-the-worlds-fastest-zk-prover-6aa5fd428609