The GPU Revolution: How We're Making Ethereum 1000x Faster with Zero-Knowledge Proofs
Today I want to share something that's been keeping me incredibly excited - a breakthrough that could literally change how we think about blockchain scalability. If you've ever wondered why Ethereum can feel slow or expensive, or if you're curious about the tech that will power the next generation of blockchain, this one's for you!
The Problem: Why Blockchains Are Like Traffic Jams
Imagine Ethereum as a highway. Right now, everyone's trying to use the same lanes, causing massive congestion. The traditional solution? Build more lanes (Layer 2s) or make cars smaller (compression). But what if we could teleport some cars instead?
That's where zero-knowledge proofs come in - they're like teleportation for data. Instead of sending all the traffic through the highway, we can prove that transactions happened without actually showing all the details. Cool, right?
Enter The Verge: Ethereum's Master Plan
Ethereum's got this ambitious roadmap called "The Verge" - think of it as Ethereum's fitness plan to get lean and mean. The goal? Make running an Ethereum node as easy as running an app on your phone. No more needing a gaming PC just to participate in the network!
But here's the catch: to make this work, we need to perform millions of complex mathematical operations really, REALLY fast. That's where our team at Polyhedra comes in.
The Technical Challenge: Numbers That'll Blow Your Mind
Let me give you some perspective on the scale we're dealing with:
- Ethereum Consensus Verification: 90 million SHA2-256 hashes + 2048 BLS signatures per block
- State Transition Proofs: ~500,000 Keccak hashes per block
- Current Bottleneck: CPU-based provers can only handle ~2 million Poseidon hashes/second
This is where things get spicy - we need to prove all these operations in zero-knowledge, which adds another layer of computational complexity!
The Breakthrough: GPUs to the Rescue!
You know those graphics cards gamers love? Turns out they're not just great for rendering your favorite games - they're absolute beasts at the kind of math we need for zero-knowledge proofs.
Here's what we achieved (warning: mind-blowing numbers ahead):
The Speed Gains Are INSANE
- 362x faster for basic operations (Mersenne31 field)
- Up to 2,826x faster for complex cryptographic operations (BN254 field)
- What used to take 21 minutes now takes just 450 milliseconds
To put this in perspective: imagine if your morning commute went from 20 minutes to less than half a second. That's the level of improvement we're talking about!
Why This Matters for YOU
1. Cheaper Transactions
Faster proof generation = lower costs = cheaper gas fees. Win-win!
2. Better Security
Remember the $40 million security budget I mentioned? With our tech, light clients can verify the ENTIRE Ethereum consensus (backed by billions in security) without breaking a sweat.
3. Phone-Friendly Ethereum
Our optimizations bring us closer to running Ethereum nodes on regular devices. Imagine verifying blockchain data on your smartphone!
The Secret Sauce: How We Did It 🧪
Without getting too nerdy (okay, maybe a little nerdy), here's the magic:
1. We speak GPU: CUDA-Optimized Sumcheck Protocol
Our Sumcheck CUDA implementation leverages massive parallelism:
- Custom CUDA kernels for field arithmetic (addition, multiplication, exponentiation)
- Coalesced memory access patterns to maximize GPU memory bandwidth (up to 1008 GB/s on RTX 4090)
- Warp-level primitives for efficient reduction operations
2. Memory is King: Bandwidth Optimization
We discovered that Sumcheck is fundamentally memory-bound, not compute-bound:
- Memory throughput analysis: Achieving 95%+ of theoretical GPU memory bandwidth
- Data layout optimization: Structure-of-Arrays (SoA) instead of Array-of-Structures (AoS)
- Streaming multiprocessor utilization: Balancing thread blocks for optimal occupancy
3. Field-specific optimizations: Tailored Approaches
Different cryptographic fields need different strategies:
- Mersenne31 (M31): Leveraging 31-bit arithmetic for efficient modular operations
- M31ext3: Extension field operations with minimal overhead
- BN254: Custom Montgomery multiplication for 254-bit operations
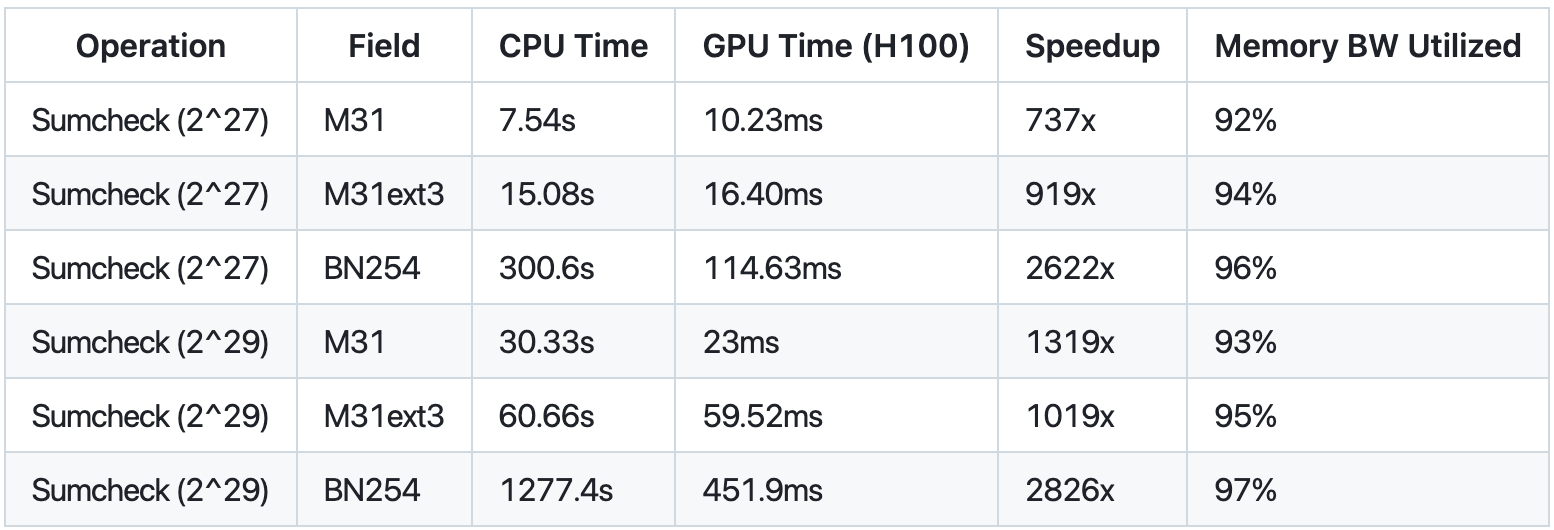
Performance Deep Dive: Where the Magic Happens 🔬
Let's look at the actual numbers from our benchmarks:
Technical Architecture: Under the Hood 🛠️
The GKR Protocol Stack
Our acceleration focuses on the GKR (Goldwasser-Kalai-Rothblum) protocol, specifically:
- Linear GKR Layer: Handling addition and multiplication gates
- Sumcheck Protocol: The workhorse that takes 50% of CPU time
- Polynomial Evaluation: Reduced from 8.4 seconds to 9.5ms on GPU
GPU Kernel Design
Phase 1: Polynomial Evaluation
- Parallel evaluation across 2^n points
- Shared memory for coefficient caching
- Warp shuffle for efficient reduction
Phase 2: Challenge Generation
- Fiat-Shamir hashing on GPU
- Minimal CPU-GPU communication overheadMemory Transfer Optimization
- PCIe overhead: Only 737ms for 2^27 elements
- Pinned memory: Zero-copy transfers where possible
- Async operations: Overlapping computation and communication
Real Talk: The Challenges 💭
Being transparent here - GPU acceleration isn't a silver bullet. Here's what we learned:
Technical Limitations We Hit
- Memory Bandwidth Saturation
- Even H100's 3.35 TB/s bandwidth becomes a bottleneck
- Larger fields (BN254) hit the wall faster than smaller ones (M31)
- GPU Memory Capacity
- RTX 4090 runs out of memory at 2^29 elements
- Need careful memory management for production systems
- Field Size vs Performance Trade-off
- M31: 23ms for 2^29 elements
- M31ext3: 59ms (2.6x slower)
- BN254: 451ms (19.6x slower than M31)
- Crossover Points (When GPU beats CPU)
- M31: Effective from 2^15 inputs
- M31ext3: Wins from 2^12 inputs
- BN254: GPU advantage from just 2^7 inputs!
Benchmarking Across Different Hardware 💻
We tested across consumer and datacenter GPUs:
Consumer GPUs
- RTX 3090: 936 GB/s memory, up to 951x speedup
- RTX 4090: 1008 GB/s memory, up to 1565x speedup
Datacenter GPUs
- H100: 3.35 TB/s memory, up to 2826x speedup
The pattern is clear: memory bandwidth is everything for ZK proof acceleration!
What's Next? The Road Ahead 🛣️
We're not stopping here. Our roadmap includes:
- Making it even faster: We're eyeing 10,000x improvements for specific operations
- Broader hardware support: From gaming GPUs to data center monsters
- Direct Ethereum integration: Working with client teams to get this into production
Join the Revolution!
This isn't just about making things faster - it's about making blockchain technology accessible to everyone. Here's how you can get involved:
For Developers: Check out our Expander and CUDA repos - contributions welcome!
For Learners: Follow our research seminars and deep dives
For Everyone: Spread the word! The more people understand this tech, the faster we can build a better Web3
The Bottom Line
We're living in exciting times. The combination of zero-knowledge proofs and GPU acceleration isn't just an incremental improvement - it's a paradigm shift. We're talking about making Ethereum faster, cheaper, and more accessible than ever before.
Key Technical Achievements:
- 1000x+ speedups for production-scale ZK proofs
- 95%+ GPU memory bandwidth utilization
- Open-source implementations ready for integration
The future of Web3 isn't just decentralized - it's FAST, and it's coming sooner than you think!
What excites you most about these developments? Drop a comment below or hit me up on Twitter - I love geeking out about this stuff!
Until next time, keep building!
Want to dive deeper? Check out our technical blog for the full details, our benchmarking data, or join our community to stay updated on the latest breakthroughs!