The Hardware Acceleration Revolution for Zero-Knowledge Proofs
Turbo-charging Privacy with GKR on FPGA & ASIC
"Speed is the currency of trust." — In zero-knowledge proof (ZKP) systems, proving fast means proving usefully.
1. Why Zero-Knowledge Proofs Need a Nitro Boost
ZKPs let one party convince another that a statement is true without revealing any additional information. They underpin private DeFi, anonymous identity, and confidential audits.
Yet vanilla software implementations are painfully slow. A mid-size proof can take seconds to minutes, stalling user experience and blocking mainstream adoption.
Enter hardware acceleration: Field-Programmable Gate Arrays (FPGAs) and Application-Specific Integrated Circuits (ASICs) transform cryptographic math into electric speed.
2. Meet GKR – The Workhorse Protocol
The Goldwasser–Kalai–Rothblum (GKR) protocol is a scalable, interactive ZKP for arbitrary arithmetic circuits.
It repeatedly applies the Sum-check protocol on multi-linear extensions (MLE) of each circuit layer.

N = gates per layer.
2.1 From O(N²) to O(N) — The Sparse Trick
A table-based implementation that materialises both halves of the log2N variables at once blows up to $2^{\log N} \times 2^{\log N} = N^2$ cross-terms.
The textbook streaming prover already needs only $\mathcal{O}(N\log N)$ work, but the sparsity trick of [Xie-Zhang-Zhang '19] drives both compute and memory down to strict $\mathcal{O}(N)$.
3. Inside a GKR Accelerator Core
┌─────────────────────────────────────┐
│ DMA / AXI Bus │ 10 GB/s
├───────────────┬─────────────────────┤
│ Dual-Port │ Dual-Port │ 1–10 MB each
│ SRAM A │ SRAM B │ (Ping–Pong Buffer)
├───────────────┴─────────────────────┤
│ Arithmetic Array (10× 256-bit MAC) │
├─────────────────────────────────────┤
│ Hardened SHA3-256 Challenge Unit │
├─────────────────────────────────────┤
│ Finite-Field & Scheduler Logic │
└─────────────────────────────────────┘
Key Pipeline Stages
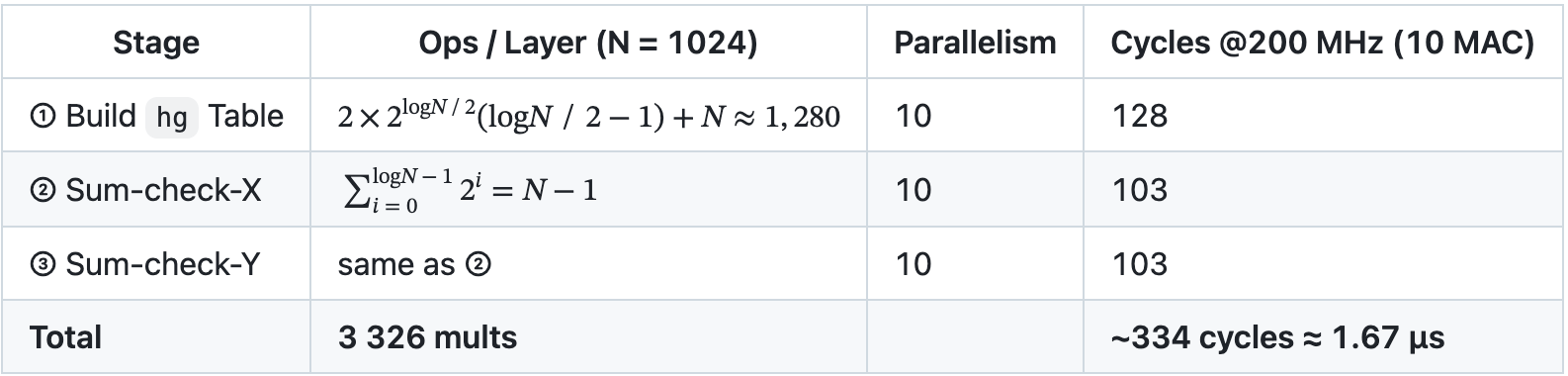
Notes:
- Ping-pong SRAM hides external DRAM latency.
- SHA3 is fully pipelined; one 256-bit digest every cycle sustains >200 M challenges/s.
- The scheduler overlaps hashing, memory copy, and arithmetic for zero idle gaps.
4. System-Level Perf & Energy
- Throughput: >5 million proof layers / second per core.
- Energy: 90 % less than CPU thanks to specialized MACs & clock gating.
- Scalability: Tile 8–64 cores per FPGA; ASICs scale to thousands.
Bandwidth Math
For a 5 MB layer and a 1.67 µs compute window:
$$
\text{BW} = \frac{5 \times 10^6 \times 8}{1.67 \times 10^{-6}} \approx 24\,\text{Tbps} \; (\approx 3\,\text{TB/s})
$$
Even with on-package HBM, such bandwidth is daunting; ping-pong SRAM and aggressive data-reuse are therefore mandatory.
5. Real-World Use Cases
- High-Frequency DeFi – sub-millisecond settlement proofs on DEXs.
- Layer-2 Roll-ups – 100–1000× TPS without trusted sequencers.
- Privacy-Preserving AI – verifiable model evaluation without leaking data.
6. Business Angle – Why Invest Now?
- Regulatory winds (MiCA, GDPR) demand provable privacy.
- FPGA costs ↓ 50 % in 3 years; cloud vendors already rent fractionally.
- Hardware IP can be licensed across blockchains, fintech, and AI security.
7. Key Takeaways
✔ 1000× speed-up vs CPU is real today.
✔ Linear-time algorithms unleash hardware friendliness.
✔ 10–15 multipliers per core are enough, thanks to Sum-check's logarithmic fan-in.
✔ SHA3 hardening prevents the hash unit from becoming the new bottleneck.
✔ Bandwidth orchestration is as critical as raw compute.
References
- J. Thaler, Time-Optimal Interactive Proofs for Circuit Evaluation, CRYPTO 2013.
- T. Xie, J. Zhang et al., Libra: Succinct ZK Proofs with Optimal Prover Computation, CRYPTO 2019.
- Z. Wang, Hardware Design Patterns for ZKP Accelerators, Micro '23.
- S. Angel et al., Streaming VC Systems, USENIX Security '22.
Curious to partner or learn more? Reach out – let's make privacy fly at the speed of light.